脳の構造を実装したAIメモリレイヤー「Cerememory」をオープンソース公開
コーレ株式会社(本社:東京都新宿区新宿4-1-6 JR新宿ミライナタワー 18階、代表取締役CEO:奥脇 真人、取締役CTO:池田 直人、設立:2017年5月17日)は2026年5月7日、AIエージェントに人間のような"生きた記憶"を与えるデータベース「Cerememory(セレメモリ)」をオープンソース(OSS)で公開した。従来のベクトルデータベースによる情報保持とは異なり、神経科学の知見をもとに脳の記憶システムを「データ構造としてではなく実行系として」再現している点が最大の特徴である。
コーレ株式会社公式プレスリリースより。画像はタップ、クリックすると拡大します
人間の記憶プロセスを再現する「5つのダイナミクス」
Cerememoryは、データを静的に保存する仕組みではなく、時間とともにふるまいを変える動的なシステムとして設計されている。実装されているダイナミクスは5つある。
第一に「忘却曲線」である。記憶の鮮度は修正べき乗則曲線に従って徐々に低下し、何度も思い出されたものは安定し、感情的に強い体験は長く残る。第二に「干渉ノイズ」である。似た記憶同士が互いの細部をぼかし合う現象を再現しており、忠実度が下がった記憶ほどノイズが乗りやすくなる。第三に「拡散活性化と再固定化」である。ある記憶を思い出すと関連する記憶が一時的に活性化し、想起された記憶は現在のコンテキストと再統合されるため、思い出すたびに微妙に変化する。
第四に「睡眠中の夢のような記憶圧縮装置」である。脳が睡眠中に一日の出来事を整理し、長期記憶へ統合するプロセスを、定期的なバックグラウンド処理として実装している。デフォルトは24時間ごとの自律実行で、手動での即時実行も可能である。第五に「感情モジュレーション」である。Robert Plutchikの感情モデルに基づく8次元の感情ベクトル(喜び・悲しみ、信頼・嫌悪、恐れ・怒り、驚き・期待の4組の対極ペア)を各記憶に紐づけ、感情強度の高い記憶ほど忘却曲線の傾きをゆるやかにする。
脳部位に対応した「5ストアアーキテクチャ」
Cerememoryは記憶の性質に応じて、脳の部位に対応した5つの専門ストアに情報を振り分ける。「Episodic」は海馬に対応し、いつ・どこで・何が起きたかという時系列のイベントを記録する。「Semantic」は大脳新皮質に対応し、事実や概念、関係性の知識をグラフ構造で保持する。「Procedural」は大脳基底核に対応し、やり方、習慣、好みのパターンを扱う。「Emotional」は扁桃体に対応し、感情のメタデータとして他のストアの記憶の強さを横断的に調整する。「Working」は前頭前皮質に対応し、高速な作業用の短期メモリ(LRU方式・インメモリ)として機能する。
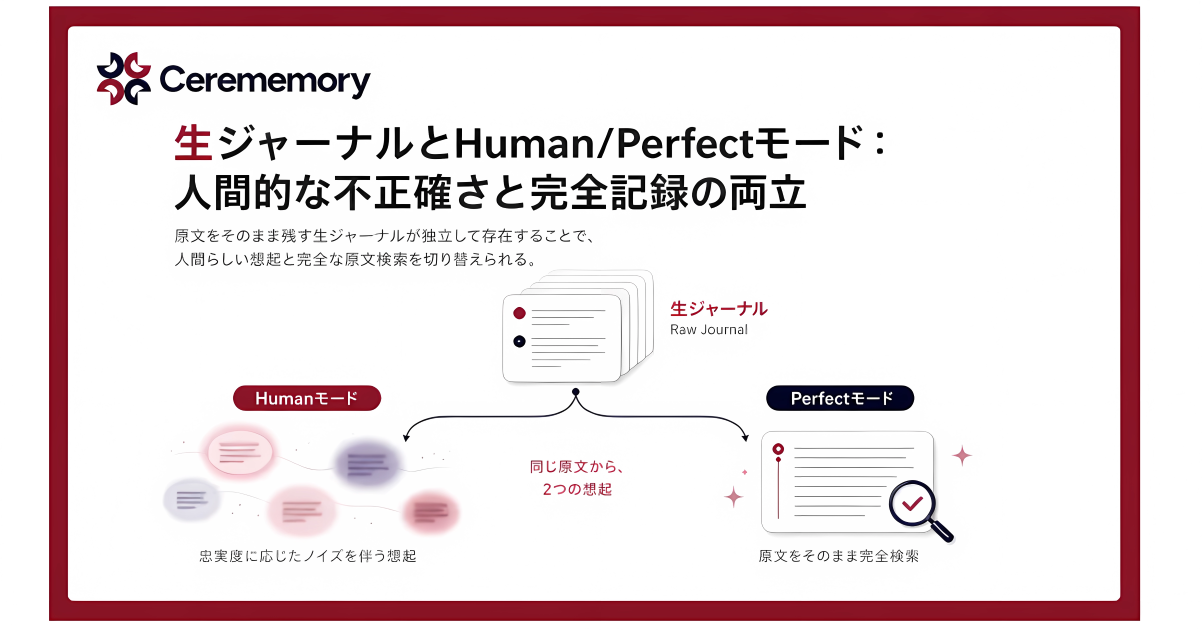
これら5ストアに加えて、原文の会話・ツール出力・スクラッチパッドをそのまま保存する「生ジャーナル(Raw Journal)」が独立したフォレンジック層として並走する。要約は5ストアへ、原文は生ジャーナルへ振り分けられ、両者はバックリンクでつながっており、要約から原文へ1ホップで戻れる構造になっている。これにより想起時には、忠実度に応じたノイズを伴う人間の記憶に近い「Humanモード」と、原文の完全な検索が可能な「Perfectモード」を使い分けることができる。
独自プロトコル「CMP」によるLLMからの独立
Cerememoryは「CMP(Cerememory Protocol)」というトランスポート非依存の独自プロトコルを中心に据えている。Anthropicが提唱したMCP(Model Context Protocol)はLLMと外部ツールをつなぐためのオープン仕様であり、両者は競合する関係ではない。Cerememoryでは「MCPがCMPを運ぶ」位置づけとなっており、HTTP/REST、gRPC、MCPの3つはCMPメッセージを運ぶバインディングとして並ぶ。HTTPとgRPCはCMPの全面(encode/recall/lifecycle/introspectの4カテゴリ)を公開し、MCPはAIエージェント向けに選定されたサブセットを提供する。
これにより、Claude、GPT、Geminiといった任意のLLMから同じ記憶層にアクセスできる。Claude Code、Codex、Gemini CLI、Cursor、Windsurfなど、任意のMCPクライアントから利用可能である。データはローカルに保存され、いつでもエクスポート可能なため、AIを乗り換えてもサービスを解約しても、記憶はユーザー自身のもとに残り続ける設計となっている。
「内容」ではなく「理由」で記憶を検索
Cerememoryのもう一つの特徴は、すべての記憶レコードに「なぜこの記憶が存在するのか」を構造化して記録するメタメモリプレーンが付随する点である。意図(intent)、根拠(rationale)、エビデンス(evidence)、代替案(alternatives)、決定(decisions)、型付きコンテキストグラフが索引されるため、エージェントは「何が書かれているか」だけでなく「なぜそう判断されたか」で記憶を辿ることができる。
開発の背景
AIエージェントのコンテキスト管理や記憶システム構築は世界中の開発者が取り組む難題であり、ベストプラクティスは未確立の状況にある。コーレは、日本から世界に向けて、次の時代のAIと人の関係を支える記憶システムを送り出したいと考え、世界中の技術者が共に磨き上げられる形でCerememoryをオープンソース公開した。
実装言語はRust、ストレージはredb、検索はTantivyとredb上の決定論的コサインインデックスを採用している。ソースコードはGitHubで公開されており、コミュニティからのフィードバックおよびコントリビューションを歓迎している。公式ドキュメントは https://co-r-e.github.io/cerememory-docs/ja 、 GitHubリポジトリは https://github.com/co-r-e/cerememory にて公開されている。
